
Q-Learning-APL
Warning : Attempt failed. Detail description here.
Q
Concept
prototype of Autonomous Parking Lot
Develop Environment
Followed two tutorial(link)
Toy Car: Yahboom Car(link) with Raspberry pi 4b
GPU: GTX 1080ti 11GB
Summary
 final
final
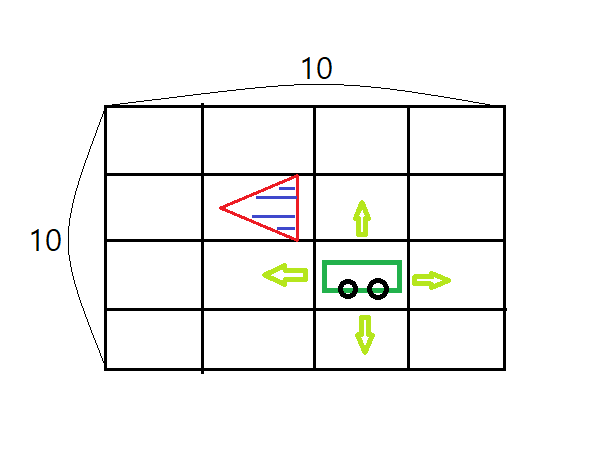
Parked state as sign(red triangle with 4 blue stripes)
car moves 10 * 10 virtual space
- up
- down
- right
- left
Code Explanation
Developed as three parts
- operation of car(direct control of motors)
- Q-learning part
- inform that car is parked(terminal state)
car operation
below method move the car.
def Car_Action(self, act_num):
if(act_num == 0):
#forward
elif(act_num == 1):
#back
elif(act_num == 2):
#left
elif(act_num == 3):
#right
Q-learning
import numpy as np
EPISODES = 15
MAX_STEPS = 10
LEARNING_RATE = 0.81
GAMMA = 0.96
Q = np.zeros(100, 4)# 10 * 10 states, 4 actions
for episode in range(EPISODES):
state = 5#initial state
for _ in range(MAX_STEPS):
car.Car_Action(action)
next_state = step(state, action)
Q[state, action] = Q[state, action] + LEARNING_RATE * (reward + GAMMA * np.max(Q[next_state, :]) - Q[state, action])
state = next_state
Simplified Q-learning code(full code here)
reward will be explained below
parked state
from tflite_runtime.interpreter import Interpreter
interpreter = Interpreter('detect.tflite')
interpreter.allocate_tensors()
_, input_height, input_width, _ = interpreter.get_input_details()[0]['shape']
res = detect_objects(interpreter, img, 0.8)
Using tflite model, detect Sign.
Parked_State_Reward = 188200
reward = ((resMat[small][0] - resMat[small][1]) **2 + (resMat[small][2] - resMat[small][3]) ** 2) / Parked_State_Reward
Assume car is parked when detected sign is biggest.
“resMat” can have multiple detections(rows), due to model’s inaccuracy or threshold of 0.8. Model’s most accurate detection was smallest one.
Material
TensorFlow 2.0 Complete Course - Python Neural Networks for Beginners Tutorial
Tensorflow Object Detection in 5 Hours with Python
https://github.com/nicknochnack/TFODCourse
After thoughts
Why it failed
First, driving is contiunous action, which using q-table is doomed to fail. Second, car can’t spin in place. Last, can’t operate more than one car.
All of the above problems stem from Q-learning using q-table.
Why, why it failed
Should’ve focus on problem, not solution.
In other words, I was too exicted that i learned something, i’ve become somekind of zealot.
Such as “Q-learning is only and best solution, which can be applied to all problem!” or “Even considering another aproach is HERESY!”